

ABAPのAPPENDコマンドとは
内部テーブルの基本概念とAPPENDの役割
ABAP開発において、内部テーブルは最も重要なデータ構造の1つです。内部テーブルはメモリ上に一時的に作成されるテーブルで、データの一時保存や加工に使用されます。この内部テーブルを操作する上で、APPENDコマンドは最も基本的かつ重要なコマンドの1つとなっています。
APPENDコマンドの主な役割は以下の通りです:
- 内部テーブルの末尾に新しい行を追加
- 構造体やワークエリアのデータを内部テーブルに追加
- 初期値を持つ新しい行の追加
- インライン宣言を使用した追加(ABAP 7.40以降)
基本的な構文:
APPEND wa_structure TO itab. * または APPEND INITIAL LINE TO itab.
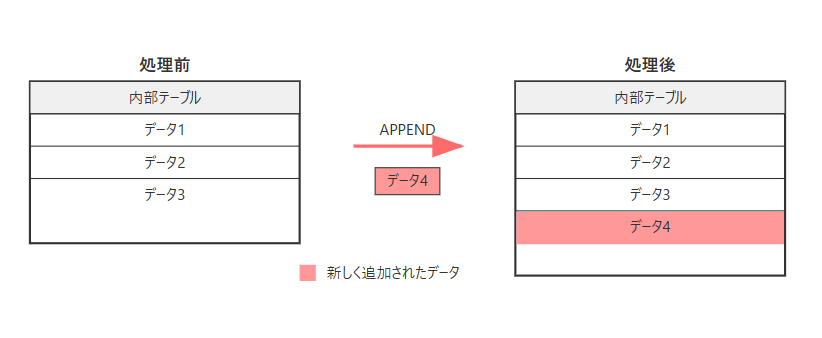
APPENDコマンドの処理イメージ
- 内部テーブルの末尾に新しい行を追加
- 構造体やワークエリアのデータを内部テーブルに追加
- 初期値を持つ新しい行の追加
- インライン宣言を使用した追加(ABAP 7.40以降)

これらの基本概念を理解することで、APPENDコマンドを効果的に活用し、効率的な内部テーブル操作を実現することができます。
単一レコードの更新パターン
APPENDコマンドによる単一レコードのそれぞれの更新パターンについて、用途と具体的な実装方法を説明します。
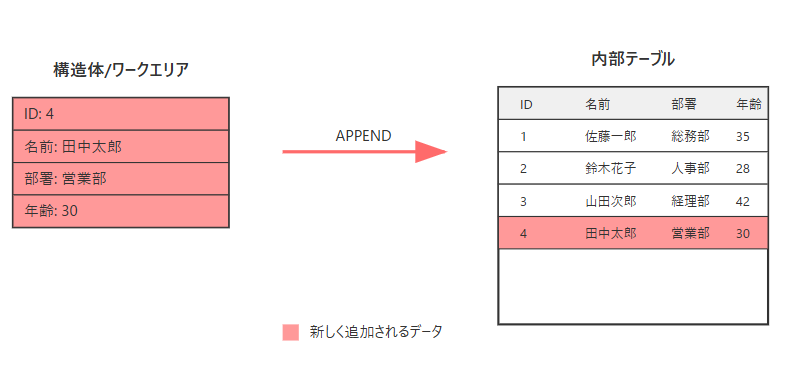
1. 構造体やワークエリアのデータを内部テーブルに追加
データの加工や条件分岐が必要な場合に適した方法です。
" 構文 DATA: ls_workarea TYPE <structure_type>. APPEND ls_workarea TO <internal_table>. " 例 DATA: ls_employee TYPE ty_employee. " ワークエリアにデータを設定 ls_employee-id = 2. ls_employee-name = 'Jane'. ls_employee-department = 'HR'. " ワークエリアの内容をテーブルに追加 APPEND ls_employee TO lt_employees.
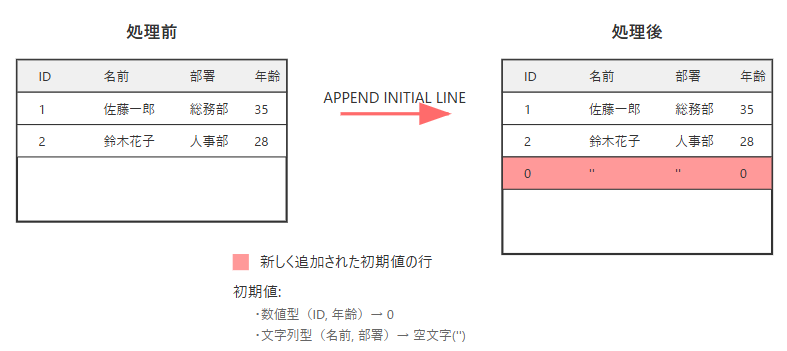
2. 初期値を持つ新しい行の追加
新規レコードを作成し、後からデータを設定する場合に使用します。
" 構文 APPEND INITIAL LINE TO <internal_table>. " 例 " 数値型フィールド → 0、文字列型フィールド → 空文字で初期化された行が追加される APPEND INITIAL LINE TO lt_employees.
3. インライン宣言を使用した追加(ABAP 7.40以降)
モダンなABAPで推奨される方法で、コードが簡潔になります。
" 構文 APPEND VALUE <type>( <field1> = <value1> <field2> = <value2> ... ) TO <internal_table>. " 例 " 単一行の追加 APPEND VALUE ty_employee( id = 3 name = 'Mike' department = 'Sales' ) TO lt_employees. " 複数行の一括追加 APPEND LINES OF VALUE tt_employee( ( id = 4 name = 'Tom' department = 'IT' ) ( id = 5 name = 'Sara' department = 'HR' ) ) TO lt_employees.
効率的なプログラミングが可能になります。次のセクションでは、より実践的なプログラミング手法について説明していきます。
APPENDを使用した実践的なプログラミング手法
ループ内でのAPPENDの効率的な使用方法
ループ内でのAPPENDコマンドの使用は非常に一般的ですが、適切な実装が重要です。以下に効率的な使用方法を示します:
" 基本的なデータ構造の定義
TYPES: BEGIN OF ty_sales,
sales_id TYPE i,
product_id TYPE string,
quantity TYPE i,
amount TYPE p DECIMALS 2,
posting_date TYPE d,
END OF ty_sales.
" テーブル定義
DATA: lt_sales_raw TYPE TABLE OF ty_sales, "元データ
lt_sales_proc TYPE TABLE OF ty_sales. "処理後データ
* 1. 非効率な実装例(アンチパターン)
LOOP AT lt_sales_raw INTO DATA(ls_sale).
" 毎回個別にAPPEND(非推奨)
APPEND ls_sale TO lt_sales_proc. "※メモリの再割り当てが頻繁に発生
ENDLOOP.
* 2. 効率的な実装例1: 初期サイズの設定
" テーブルの初期サイズを設定して効率化
DATA(lv_expected_size) = lines( lt_sales_raw ).
lt_sales_proc = VALUE #( LEN = lv_expected_size ). "メモリを事前確保
" ループ処理
LOOP AT lt_sales_raw INTO ls_sale.
APPEND ls_sale TO lt_sales_proc. "メモリ再割り当てが発生しない
ENDLOOP.
* 3. 効率的な実装例2: バッファリングを使用した一括処理
CONSTANTS: lc_buffer_size TYPE i VALUE 1000. "バッファサイズ
DATA: lt_buffer TYPE TABLE OF ty_sales. "バッファテーブル
DATA: lv_counter TYPE i VALUE 0. "カウンター
LOOP AT lt_sales_raw INTO ls_sale.
" バッファにデータを追加
APPEND ls_sale TO lt_buffer.
lv_counter += 1.
" バッファがいっぱいになったら一括処理
IF lv_counter >= lc_buffer_size.
" バッファのデータを一括でメインテーブルに追加
APPEND LINES OF lt_buffer TO lt_sales_proc.
CLEAR: lt_buffer, lv_counter.
" コミット(必要に応じて)
COMMIT WORK AND WAIT.
ENDIF.
ENDLOOP.
" 残りのバッファデータを処理
IF lt_buffer IS NOT INITIAL.
APPEND LINES OF lt_buffer TO lt_sales_proc.
ENDIF.
条件付きデータ追加の実装例
条件付きデータ追加は、ビジネスロジックを実装する上で重要な手法です:
* 1. 基本的な条件付き追加
LOOP AT lt_items INTO DATA(ls_item).
" 価格が1000以上の商品のみを追加
IF ls_item-price >= 1000.
APPEND ls_item TO lt_expensive_items.
ENDIF.
ENDLOOP.
* 2. 複数条件での追加
DATA: lt_valid_orders TYPE TABLE OF ty_order.
LOOP AT lt_orders INTO DATA(ls_order).
" 複合条件チェック
IF ls_order-status = 'A' AND "アクティブ注文
ls_order-amount > 0 AND "金額あり
ls_order-delivery_date >= sy-datum. "未配送
APPEND ls_order TO lt_valid_orders.
ENDIF.
ENDLOOP.
他のテーブル操作コマンドとの組み合わせ技
APPENDを他のテーブル操作コマンドと組み合わせることで、より高度な処理が可能になります:
* 1. READ TABLEとの組み合わせ
DATA: ls_existing TYPE ty_data.
READ TABLE lt_existing INTO ls_existing
WITH KEY id = ls_new-id.
IF sy-subrc <> 0.
" 存在しない場合のみ追加
APPEND ls_new TO lt_existing.
ENDIF.
* 2. SOTRとの組み合わせ
LOOP AT lt_source INTO DATA(ls_source).
SORT lt_target BY id. "ソート
READ TABLE lt_target TRANSPORTING NO FIELDS
WITH KEY id = ls_source-id BINARY SEARCH.
IF sy-subrc <> 0.
" 重複しないデータのみ追加
APPEND ls_source TO lt_target.
ENDIF.
ENDLOOP.
* 3. DELETEとの組み合わせ
" 古いデータを削除して新しいデータを追加
DELETE lt_data WHERE date < sy-datum.
APPEND LINES OF lt_new_data TO lt_data.
実践的なテクニックまとめ:
| テクニック | 用途 | メリット |
|---|---|---|
| バッファリング | 大量データ処理 | メモリ効率とパフォーマンスの改善 |
| 条件付き追加 | ビジネスロジック実装 | データの整合性維持 |
| コマンド組み合わせ | 複雑な処理要件 | 処理の最適化と可読性向上 |
| 初期サイズ設定 | パフォーマンス最適化 | メモリ再割り当ての削減 |
APPENDの代替手法と使い分け
INSERT文との比較と適切な使用シーン
APPENDとINSERTは内部テーブルにデータを追加する代表的なコマンドです。それぞれの特徴と使い分けについて説明します。
* 1. APPEND vs INSERT の基本的な使い方 DATA: lt_data TYPE TABLE OF ty_data. " APPENDの場合(末尾に追加) APPEND VALUE ty_data( id = 1 name = 'Test' ) TO lt_data. " INSERTの場合(位置指定可能) INSERT VALUE ty_data( id = 2 name = 'Test2' ) INTO lt_data INDEX 1.
テーブル型別のAPPEND/INSERT操作可否
| テーブル型 | APPEND | INSERT | 説明 |
|---|---|---|---|
| 標準テーブル | ◎ | ◯ | APPENDが最適。末尾への追加が高速 |
| ソートテーブル | △ | ◎ | INSERTを推奨。ソート順を維持 |
| ハッシュテーブル | × | ◎ | APPENDは使用不可。INSERTのみ使用可能 |
凡例
- ◎:最適(推奨される使用方法)
- ◯:使用可能(問題なく使用できる)
- △:条件付き使用可能(使用可能だが推奨されない)
- ×:使用不可(エラーとなる)
テーブル型別の特徴と制約
- 標準テーブル(Standard Table)
- APPEND: 最適な選択
- INSERT: 位置指定が必要な場合に使用
- 制約なし
- ソートテーブル(Sorted Table)
- APPEND: 非推奨(ソート順が崩れる可能性)
- INSERT: 推奨(自動的にソート順を維持)
- キーに基づいてソートされた状態を維持
- ハッシュテーブル(Hashed Table)
- APPEND: 使用不可
- INSERT: 必須
- ハッシュキーによる一意性を維持
コード例:テーブル型による動作の違い
"----------------------------------------------------------------------
" 各テーブル型の宣言と操作例
"----------------------------------------------------------------------
TYPES: BEGIN OF ty_data,
id TYPE i,
name TYPE string,
END OF ty_data.
" 1. 標準テーブル - APPEND/INSERT両方使用可能
DATA: lt_standard TYPE STANDARD TABLE OF ty_data.
" APPENDが可能
APPEND VALUE ty_data( id = 1 name = 'Test' ) TO lt_standard. "OK
" INSERTも可能
INSERT VALUE ty_data( id = 2 name = 'Test2' ) INTO lt_standard INDEX 1. "OK
" 2. ソートテーブル - INSERTを推奨
DATA: lt_sorted TYPE SORTED TABLE OF ty_data WITH UNIQUE KEY id.
" APPENDは可能だが非推奨
" (ソート順が崩れる可能性があるため警告が出る)
APPEND VALUE ty_data( id = 1 name = 'Test' ) TO lt_sorted. "警告
" INSERTが推奨される使用方法
INSERT VALUE ty_data( id = 2 name = 'Test2' ) INTO TABLE lt_sorted. "OK
" 3. ハッシュテーブル - INSERT必須
DATA: lt_hashed TYPE HASHED TABLE OF ty_data WITH UNIQUE KEY id.
" APPENDは使用不可
" 以下のコードはコンパイルエラー
" APPEND VALUE ty_data( id = 1 name = 'Test' ) TO lt_hashed. "エラー
" INSERTが唯一の追加方法
INSERT VALUE ty_data( id = 1 name = 'Test' ) INTO TABLE lt_hashed. "OK
エラーと警告
- ハッシュテーブルでのAPPEND使用時:
- コンパイルエラーが発生
- 「APPENDはハッシュテーブルでは使用できません」というメッセージ
- ソートテーブルでのAPPEND使用時:
- 警告メッセージが表示される
- データの整合性が保証されない可能性がある

